NEWS
2017.08.23 プレス
学習によって識字率がアップするAIサービス手書き文字をデータ化する「Tegaki」提供開始
手書き文字の認識率99.22%*の研究を元に
データ入力作業の効率化とコスト削減を実現
株式会社Cogent Labs(本社:東京都渋谷区、代表取締役:飯沼純、エリック ホワイトウェイ、以下「コージェントラボ」)は、2017年8月より、手書き文字を高精度でデータ化する「Tegaki(https://tegaki.ai)」の一般販売を開始いたします。
「Tegaki」は、既存技術では自動認識による読み取りが難しくキーボード入力が必要だった手書き文字を、スピーディーに高精度でデータ化します。独自開発のAI技術でデータを処理・学習することによって、読み取り精度は、継続的に向上します。
コージェントラボは「Tegaki」を通じて、データ入力にかかる業務の効率化とコスト削減、労働生産性の向上を、業界を問わず実現します。
*「Tegaki」の認識率について、すべての手書き帳票で初回から99.22%の認識率を保証するものではありません。99.22%の認識率については末尾をご覧ください。
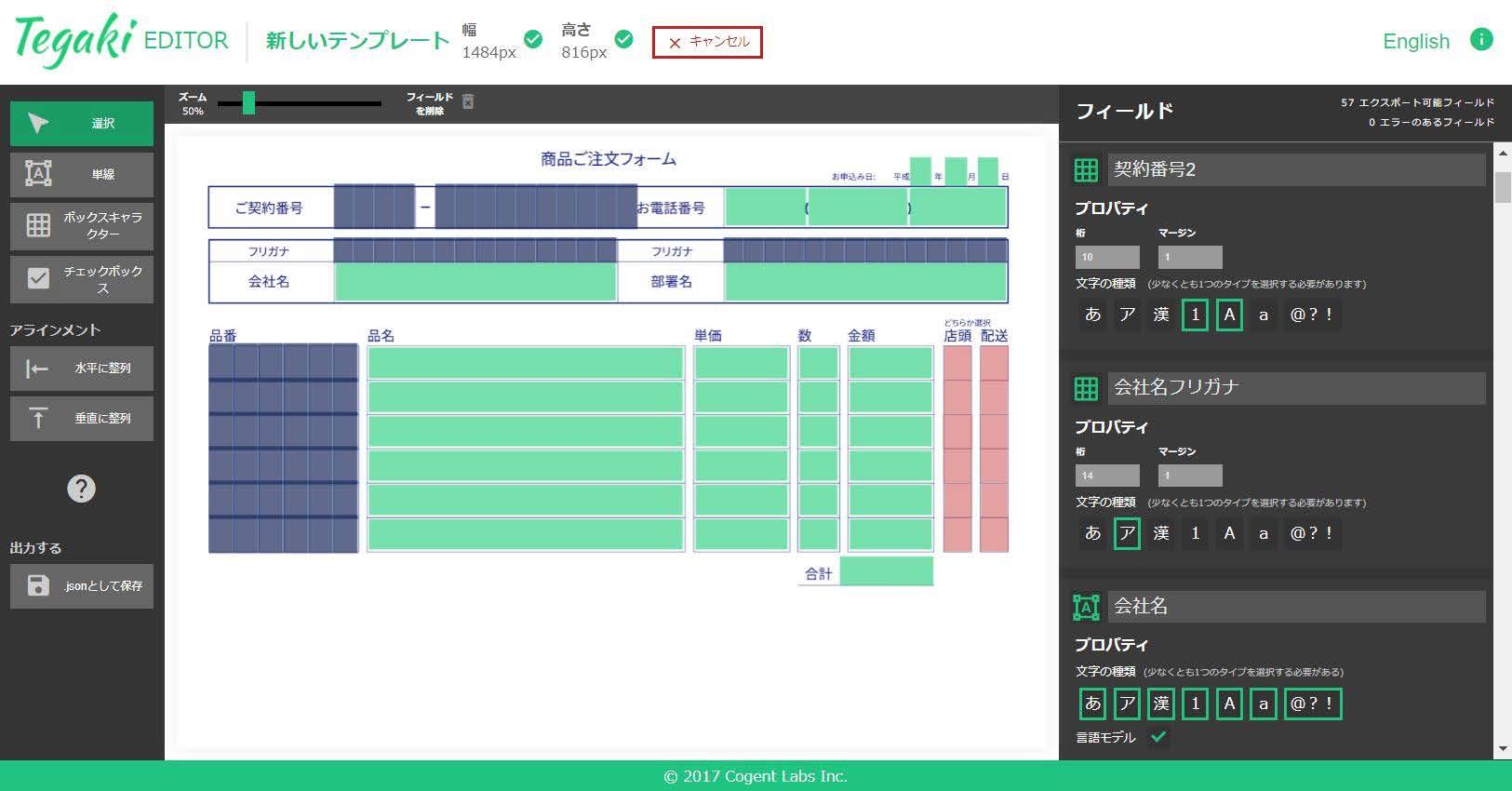
Tegaki利用イメージ(フォーム設定画面)
サービス概要
「Tegaki」は、製造、販売、金融、医療、サービス、教育など、あらゆる業界で使われている、手書き帳票に書かれた文字を高精度に認識できるサービスとして開発しました。手書き文字と活字を同時に認識することが可能です。 読み取りたい帳票はWEBブラウザ上で指定します。データの認識と読み取り結果はAPIで提供しており、現在ご利用中のシステムと接続して手軽に導入できます。
「Tegaki」4つの特徴
☑️学習性 : 読み取り精度の継続的な向上:ディープラーニングを活用したアルゴリズムから構成され、データを処理しながら学習することで、読み取り精度が継続的に向上。
☑️拡張性 : 他言語への対応:トレーニングデータを準備する事で各種他言語の手書き文字読み取りへの適用可能。業界用語への対応:言語モデルを備えており、業界特有の言語モデルと連携すれば読み取り精度を高めることが可能。
☑️利便性 : プロセスの簡素化:活字・手書き文字双方に加え、チェックボックス・丸囲い文字などを一つのサービスで読み取れるため、フォーム毎OCRとの使い分けや選別をする手間が不要。
☑️経済性 : コスト削減:シングルライン10文字(ひらがな5文字、カタカナ5文字)の場合、人による入力は17.6円~のところ、tegakiでは1円以下と、およそ94%のコスト削減を実現(※1)
コージェントラボでは、これまでに十数社とPoC(Proof of Concept:コンセプト検証)を実施、さまざまな検証を重ねて今回のサービス開始に至りました。すでに検証を経て、複数社に導入が決まり、他にも多くの企業が導入検討を進めています。「Tegaki」は、銀行口座・クレジットカードなど金融機関や電気・ガス・水道など公共料金の申込書、お客様の声やアンケートの用紙、病院の問診票や診断書、テスト答案など、幅広いシーンでの活用を想定しています。
※1 日本データエントリー協会 平成28年(2016年)度 データエントリー料金資料より(https://www.jdea.gr.jp/index.html)
サービス価格
いくつかのプランをご用意しています。スタンダードタイプは月額20万円(20万円分のデータ化費用含む)から。1フィールドはボックスキャラクター0.2円、シングルライン0.8円となります。帳票1枚当たりのデータ化費用は、その帳票のフィールド数とフィールドのタイプによって異なります。 エンタープライズ版では、セキュリティおよび個人情報保護などへの対応について、個別に専任担当がついて導入まで相談/サポートさせて頂きます。エンタープライズ版の価格は個別にお見積りとなります。
フィールドのタイプについて

参考
増え続けているドキュメント処理の需要
マイナンバー関連業務、ストレスチェック制度の導入、電力小売/ガス小売自由化などの制度改革に伴いドキュメントは増え続けており、国内ドキュメントアウトソーシングサービス市場の2015年~2020年の年間平均成長率は7.1%、2020年の市場規模は4,023億4,500万円と見込まれています。(※2)
企業に業務改善としてのドキュメント処理効率化ニーズが元々ある中、このようにドキュメントが増えることによって、インソーシング、アウトソーシングともデータ入力業務は増えており、コージェントラボが2016年6月にAIによる手書き認識についての研究を発表して以来、多くの問い合わせを頂いておりました。
※2 IDCより(http://www.idcjapan.co.jp/Press/Current/20161026Apr.html)
認識率99.22%について
コージェントラボの開発したエンジンを使用して下記の文章を認識した場合の認識率は99.22%となります。
元の手書き(5人の筆跡) 認識結果

本件に関する報道関係者からの問い合わせ先
株式会社 Cogent Labs
Tel:03-6773-1836
メール:[email protected]